Sparse approximation
Sparse approximation (also referred to as sparse decomposition) is the problem of estimating a sparse multi-dimensional vector, satisfying a linear system of equations given high-dimensional observed data and a design matrix. Sparse approximation techniques have found wide use in applications such as image processing, audio processing, biology, and document analysis.
Contents |
Sparse decomposition
Noiseless observations
Consider a linear system of equations 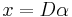 , where
, where 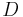 is an
is an 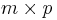 matrix
matrix 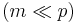 and
and 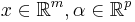 . , called as the dictionary or the design matrix, is given. The problem is to estimate the signal
. , called as the dictionary or the design matrix, is given. The problem is to estimate the signal  , subject to the constraint that it is sparse. The underlying motivation for sparse decomposition problems is that even though the observed values are in high-dimensional
, subject to the constraint that it is sparse. The underlying motivation for sparse decomposition problems is that even though the observed values are in high-dimensional 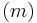 space, the actual signal is organized in some lower-dimensional subspace
space, the actual signal is organized in some lower-dimensional subspace 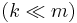 .
.
Sparsity implies that only a few components of  are non-zero and the rest are zero. This implies that can be decomposed as a linear combination of only a few
are non-zero and the rest are zero. This implies that can be decomposed as a linear combination of only a few 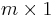 vectors in , called atoms. itself is over-complete
vectors in , called atoms. itself is over-complete  Such vectors are called as the basis of . However, unlike other dimensionality reducing decomposition techniques such as Principal Component Analysis, the basis vectors are not required to be orthogonal.
Such vectors are called as the basis of . However, unlike other dimensionality reducing decomposition techniques such as Principal Component Analysis, the basis vectors are not required to be orthogonal.
The sparse decomposition problem is represented as,
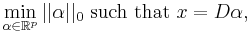
where 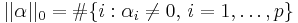 is a pseudo-norm,
is a pseudo-norm,  , which counts the number of non-zero components of
, which counts the number of non-zero components of ![\alpha = [\alpha_1,\ldots,\alpha_p]^T](/2012-wikipedia_en_all_nopic_01_2012/I/47d8b822f427a3cb50d95ac7af0b8114.png) . This problem is NP-Hard with a reduction to NP-complete subset selection problems in combinatorial optimization. A convex relaxation of the problem can instead be obtained by taking the
. This problem is NP-Hard with a reduction to NP-complete subset selection problems in combinatorial optimization. A convex relaxation of the problem can instead be obtained by taking the 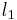 norm instead of the norm, where
norm instead of the norm, where 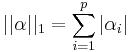 . The norm induces sparsity under certain conditions[1].
. The norm induces sparsity under certain conditions[1].
Noisy observations
Often the observations are noisy. By imposing an 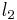 norm on the data-fitting term and relaxing the equality constraint, the sparse decomposition problem is given by,
norm on the data-fitting term and relaxing the equality constraint, the sparse decomposition problem is given by,
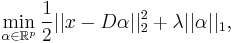
where 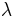 is a slack variable and
is a slack variable and 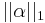 is the sparsity-inducing term. The slack variable balances the trade-off between fitting the data perfectly, and employing a sparse solution.
is the sparsity-inducing term. The slack variable balances the trade-off between fitting the data perfectly, and employing a sparse solution.
Variations
There are several variations to the basic sparse approximation problem.
Structured sparsity
In the original version of the problem, any atoms in the dictionary can be picked. In the structured (block) sparsity model, instead of picking atoms individually, groups of atoms are to be picked. These groups can be overlapping and of varying size. The objective is to represent such that it is sparse in the number of groups selected. Such groups appear naturally in many problems. For example, in object classification problems the atoms can represent images, and groups can represent category of objects.
Collaborative sparse coding
The original version of the problem is defined for only a single point and its noisy observation. Often, a single point can have more than one sparse representation with similar data fitting errors. In the collaborative sparse coding model, more than one observation of the same point is available. Hence, the data fitting error is defined as the sum of the norm for all points.
Algorithms
There are several algorithms that have been developed for solving sparse approximation problem.
Matching pursuit
Matching Pursuit is a greedy iterative algorithm for approximatively solving the original pseudo-norm problem. Matching pursuit works by finding a basis vector in that maximizes the correlation with the residual (initialized to ), and then recomputing the residual and coefficients by projecting the residual on all atoms in the dictionary using existing coefficients. Matching pursuit suffers from the drawback that an atom can be picked multiple times which is addressed in orthogonal matching pursuit.
Orthogonal matching pursuit
Orthogonal Matching Pursuit is similar to Matching Pursuit, except that an atom once picked, cannot be picked again. The algorithm maintains an active set of atoms already picked, and adds a new atom at each iteration. The residual is projected on to a linear combination of all atoms in the active set, so that an orthogonal updated residual is obtained. Both Matching Pursuit and Orthogonal Matching Pursuit use the norm.
LASSO
LASSO method solves the norm version of the problem. In LASSO, instead of projecting the residual on some atom as in Matching Pursuit, the residual is moved by a small step in the direction of the atom iteratively.
Other methods
There are several other methods for solving sparse decomposition problems [2]
- Homotopy method
- Coordinate descent
- First order/proximal methods
- Dantzig selector[3]
References
- ^ Donoho, D.L. (2006). "For most large underdetermined systems of linear equations the minimal l1-norm solution is also the sparsest solution". Communications on pure and applied mathematics (Wiley Online Library) 56 (6): 797–829.
- ^ Francis Bach, Julien Mairal, Jean Ponce and Guillermo Sapiro. "Sparse Coding and Dictionary Learning for Image Analysis". http://www.di.ens.fr/~mairal/tutorial_iccv09/tuto_part1.pdf.
- ^ Candes, Emmanuel; Tao, Terence (2007). "The Dantzig selector: Statistical estimation when p is much larger than n". Annals of Statistics 35 (6): 2313–2351. arXiv:math/0506081. doi:10.1214/009053606000001523. MR2382644.
|
||||||||||||||